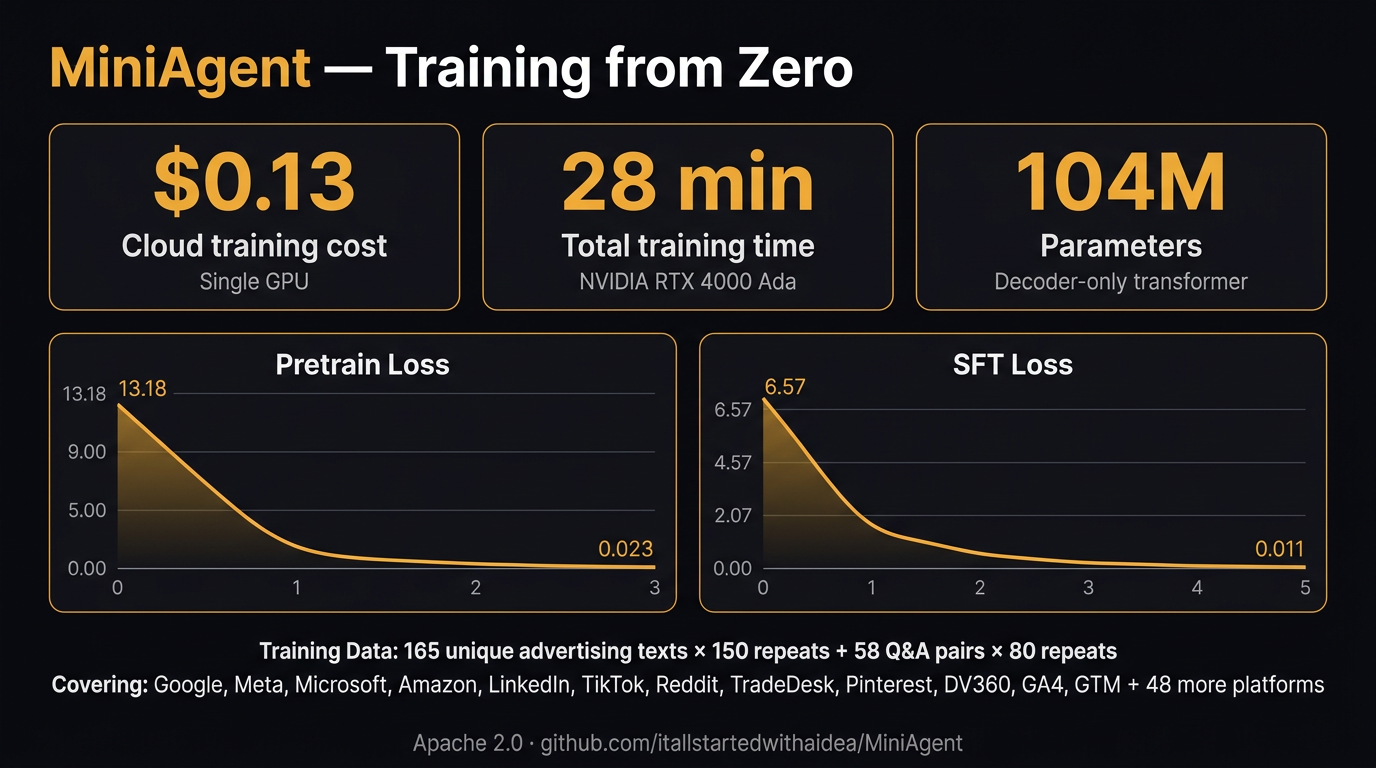
Here's something that would've sounded absurd two years ago: you can train a domain-specific AI model from zero, on a single GPU, in 28 minutes, for thirteen cents. Not fine-tune someone else's model. Train. From blank weights to a working advertising intelligence engine that knows GAQL syntax, bid strategy math, and the difference between Target CPA and Maximize Conversions.
I did it. It's called MiniAgent, and it's three things crammed into one repo: a trainable LLM, 14 MCP server connectors covering every major ad platform, and a skills framework that plugs into Claude Code, Codex, and Gemini CLI. Apache 2.0. All of it.
But I want to tell this story honestly. Because "I trained an AI for $0.13" makes for a great headline and a terrible understanding of what actually happened.
I've spent 15 years managing paid media campaigns. $48 million in annual ad spend across Google, Meta, Microsoft, Amazon, and a dozen other platforms. I've watched this industry churn through dashboards, scripts, rules engines, and now AI agents — each generation promising to automate what the last one couldn't.
The AI agent wave is different. Not because the technology is better (it is), but because the tooling gap is enormous. Claude and GPT-4 can write you a GAQL query. They can't execute it against your account. They can recommend bid strategy changes. They can't look at your actual performance data to know whether the recommendation makes sense.
So I built the bridge. MiniAgent connects AI agents to real ad platform APIs, gives them domain-specific knowledge they weren't trained on, and — if you're feeling ambitious — lets you train your own model that speaks advertising natively.

MiniAgent isn't one thing pretending to be three things. It's genuinely three independent systems that happen to live in the same repository because they reinforce each other.
This is a fork of minimind — an open-source decoder-only transformer with 42,000+ GitHub stars. JingyaoGong built something remarkable: a model architecture small enough to train on a single consumer GPU (26M to 494M parameters), yet capable enough to absorb domain knowledge when you feed it the right data.
I took that architecture and retrained it on advertising. 165 unique texts covering Google Ads documentation, campaign management practices, GAQL syntax, cross-platform terminology, bid strategy mechanics, conversion tracking, and attribution modeling. Across 60+ platforms. Then I ran supervised fine-tuning on 58 instruction-response pairs built from my own practitioner expertise — the kind of stuff you learn after auditing a few hundred accounts.
I should be straight about what this gets you. At 104M parameters with this data volume, you get a model that's absorbed advertising vocabulary and concepts — CPA, ROAS, impression share, GAQL field references, bid strategy names. It can complete advertising-related sentences coherently. It won't write you a campaign strategy brief that rivals Claude 4. That's not the point.
The point is proof of concept. Each iteration with more training data improves output quality. The 494M variant (built on Qwen2.5-0.5B) already shows meaningfully better coherence. And the training pipeline itself — pretrain, SFT, LoRA, DPO, GRPO, distillation — is production-grade. You can drop in your own account data and fine-tune a model that knows your campaigns.
This is the part that's already production-ready. MCP — Model Context Protocol — is the open standard that lets AI agents call external tools. Think of it as USB-C for AI: a universal interface between the model and the world.
MiniAgent ships MCP servers for 14 advertising platforms:
The Google Ads server alone gives you 29 tools: pull campaign performance, run GAQL queries, fetch keyword reports, check search term data, audit account structure, and — carefully — write changes back via a Confirm-Execute-Postcheck protocol that won't accidentally tank your account.
Installation's one command. pip install miniagent[google] for Google Ads.
pip install miniagent[all] for everything. Works with Claude Code, Cursor, Windsurf, the OpenAI
Agents SDK, LangChain — anything that speaks MCP.
Skills are structured knowledge that agents load on demand. Instead of hoping Claude figures out what "audit this Google Ads account" means from its training data, you hand it a skill file that defines exactly what a 7-dimension audit looks like, what severity ratings mean, and what a 30/60/90-day remediation plan should contain.
Five skills ship today:
They work with Claude Code, Codex, Gemini CLI, Cursor, and any agent that supports the SKILL.md standard. One-line install from the plugin marketplace or a git clone.
While MiniAgent handles the data and strategy side of advertising, there's another piece that practitioners actually spend half their day on: writing. Ad copy. Landing pages. Blog posts. Social posts. Client reports. The amount of text a paid media specialist produces is staggering, and most of it follows patterns that AI should handle — if AI could write without sounding like AI.
That's what Ghost Writer does. And v2.0 is a meaningful step up.
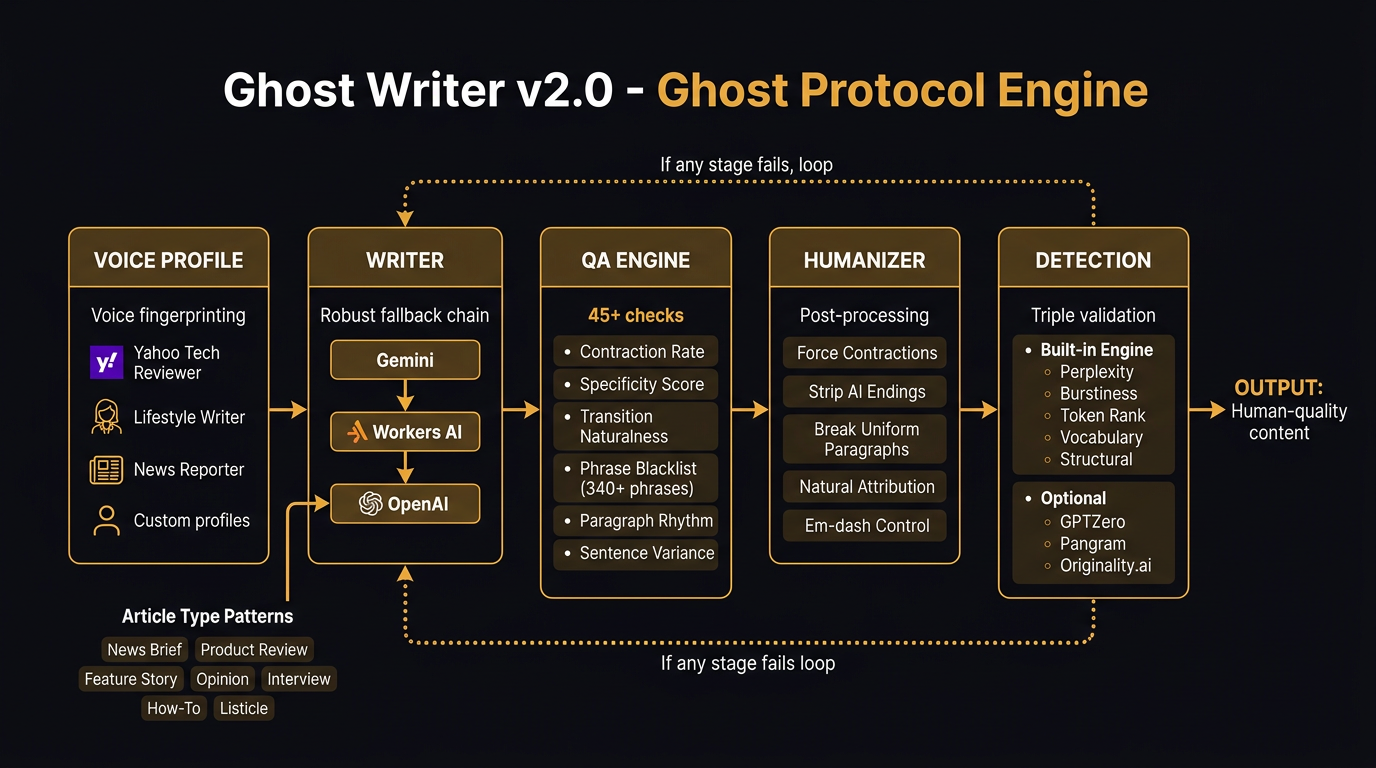
Here's what changed. I pulled apart a dozen professionally-written articles — actual Yahoo News, Engadget, lifestyle features, product reviews — and extracted every pattern that makes them read like a person wrote them. Not the obvious stuff like "don't say delve." The structural stuff. How professional writers open articles with scene-setting details instead of thesis statements. How they vary paragraph length between 1 and 6 sentences. How they drop in specific numbers ($849, 3.2 million, 14%) instead of vague quantities. How they use contractions 70-80% of the time. How their transitions are invisible, not signposted with "Furthermore" and "Moreover."
All of that's now encoded in the engine.
The QA engine runs 45+ checks now. Some are hard fails — if the contraction rate drops below 60%, the content gets kicked back. If more than 3 sentences start with "This is" or "This means," it gets kicked back. If the system detects AI hedging pairs like "exciting yet challenging" or "promising yet uncertain" — kicked back. The phrase blacklist has grown from 120 to 340+ entries.
And then there's the humanizer. It's post-processing that runs after generation, catching patterns the LLM couldn't help itself from producing. It forces contractions. Strips AI-style conclusions. Rewrites verbose attributions ("According to John Doe, who serves as the Senior Vice President of..." becomes "John Doe, Senior VP, says..."). Breaks up uniform paragraph lengths. Removes transitions that connect paragraphs too smoothly.
The detection engine scores every piece across five dimensions: perplexity, burstiness, token rank distribution, vocabulary fingerprint, and structural patterns. Optional integrations with GPTZero, Pangram, and Originality.ai for external validation.
Here's the thing that's hard to convey in a README. These aren't separate projects that happen to share a GitHub organization. They're a stack.
MiniAgent's MCP servers pull your campaign data. The agent skills know how to interpret it. Ghost Writer turns the analysis into content — LinkedIn posts about your latest campaign wins, blog articles about industry trends, client-facing reports that don't read like a template. And the trainable model? That's the long game. Your own LLM, fine-tuned on your account data, your writing style, your domain.
Right now, you'd use Claude or GPT-4 as the brain and MiniAgent as the arms and legs. Eventually, the brain gets smaller, cheaper, and specialized enough to run on your own infrastructure. That's where the $0.13 training cost matters — not because you're going to replace Claude today, but because the path from "rely on API" to "run it yourself" is 28 minutes and a single GPU.
Let me be precise about what works today versus what's coming.
Fastest path: install the Google Ads MCP server and connect it to Claude Code. You'll have a working AI agent with real API access to your campaigns in about ten minutes.
If you want the writing engine, it's already live — no install needed. Ghost Writer at ahmeego.com. Free, no sign-up, no API key.
If you want to train the model yourself, clone the repo and run the pretrain script. That's the 28-minute, $0.13 path. You'll need a GPU with at least 16GB VRAM. The RTX 3090, 4090, or any of the professional cards work fine. Cloud options: a Lambda Labs A10G instance runs about $0.40/hour.
Everything's Apache 2.0. Fork it. Extend it. Ship it commercially if you want to. The MCP servers, the skills, the training pipeline, the models — all open.
I'll be honest: MiniAgent at 104M parameters isn't replacing anyone's workflow today. It's a proof of concept. A working proof of concept with real MCP servers and real skills that are production-grade, but the model itself is early.
The roadmap is more data, more platforms, and better models. The 494M Qwen-based variant is already noticeably more coherent. The next training iteration will include more advertising corpus data, more SFT pairs, and DPO alignment against practitioner-verified good/bad advice. Each round takes two hours and costs pennies.
Meanwhile, the MCP servers and skills work right now, today, with Claude and GPT-4 and Gemini. You don't have to wait for the model to mature to get value out of the ecosystem. That was intentional. Build the connective tissue first, train the brain later.
The repo's at github.com/itallstartedwithaidea/MiniAgent. Stars and issues are both welcome. Training data contributions especially — if you've got advertising domain content that could improve the model, the dataset format is documented in the wiki.
After 15 years of managing ad campaigns manually, watching automation tools promise more than they deliver, and now building the tools myself — I think we're finally at the inflection point. Not because the AI got smarter. Because the plumbing got open.